 gyzboy的十万个为什么
gyzboy的十万个为什么
网络
- get是获取数据,post是修改数据
- get把请求的数据放在url上, 以?分割URL和传输数据,参数之间以&相连,所以get不太安全。而post把数据放在HTTP的包体内(requrest body)
- get提交的数据最大是2k( 限制实际上取决于浏览器), post理论上没有限制。
- GET产生一个TCP数据包,浏览器会把http header和data一并发送出去,服务器响应200(返回数据); POST产生两个TCP数据包,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
- GET请求会被浏览器主动缓存,而POST不会,除非手动设置。
如果维持连接,一个 TCP 连接是可以发送多个 HTTP 请求的
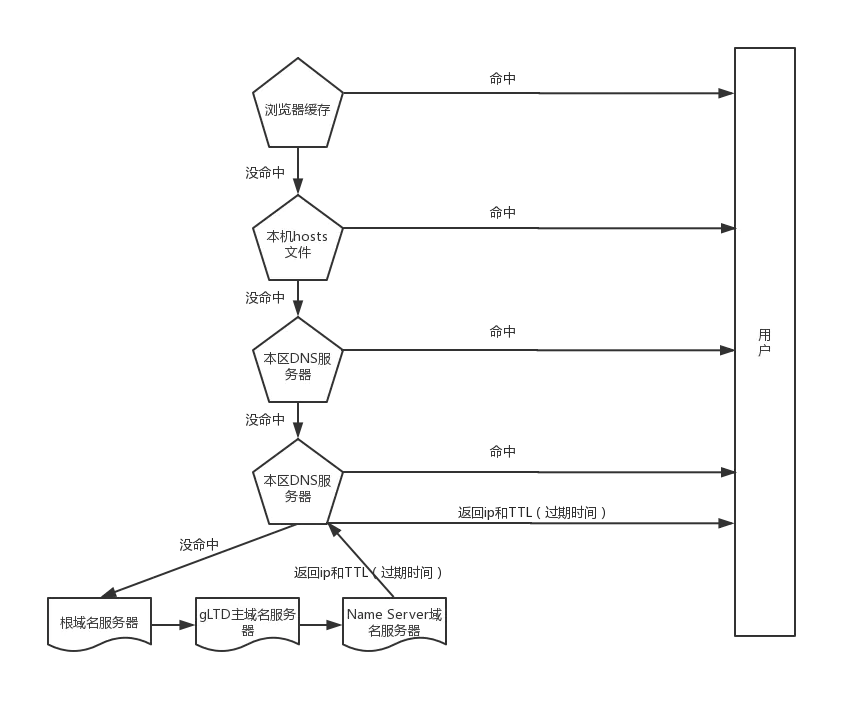
- 根据域名,进行DNS域名解析;
- 拿到解析的IP地址,建立TCP连接;
- 向IP地址,发送HTTP请求;
- 服务器处理请求;
- 返回响应结果;
- 关闭TCP连接;
- 浏览器解析HTML;
- 浏览器布局渲染;
- Last-Modified / if-Modified-Since:Expires不太稳定,浏览器端可以随意的修改Expires。 Last-Modified只能精确到秒。在极端情况下,假设文件在1s内发生了变动,那么此时 Last-Modified 就无法感知到该文件的变化,这样浏览器永远都拿不到最新的文件资源
- Etag / if-None-Match:MD5对比文件是否有所变动
其实第三次握手的时候,是可以携带数据的。但是,第一次、第二次握手不可以携带数据
为什么这样呢?大家可以想一个问题,假如第一次握手可以携带数据的话,如果有人要恶意攻击服务器,那他每次都在第一次握手中的 SYN 报文中放入大量的数据。因为攻击者根本就不理服务器的接收、发送能力是否正常,然后疯狂着重复发 SYN 报文的话,这会让服务器花费很多时间、内存空间来接收这些报文。
也就是说,第一次握手不可以放数据,其中一个简单的原因就是会让服务器更加容易受到攻击了。而对于第三次的话,此时客户端已经处于 ESTABLISHED 状态。对于客户端来说,他已经建立起连接了,并且也已经知道服务器的接收、发送能力是正常的了,所以能携带数据也没啥毛病。
任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了TCP连接。举个例子:A 和 B 打电话,通话即将结束后,A 说“我没啥要说的了”,B回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话,于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”,A 回答“知道了”,这样通话才算结束。
非对称密钥加密,又称公开密钥加密(Public-Key Encryption),加密和解密使用不同的密钥。
公开密钥所有人都可以获得,通信发送方获得接收方的公开密钥之后,就可以使用公开密钥进行加密,接收方收到通信内容后使用私有密钥解密。
非对称密钥除了用来加密,还可以用来进行签名。因为私有密钥无法被其他人获取,因此通信发送方使用其私有密钥进行签名,通信接收方使用发送方的公开密钥对签名进行解密,就能判断这个签名是否正确。
- 优点:可以更安全地将公开密钥传输给通信发送方;
- 缺点:运算速度慢。
HTTPS 采用混合的加密机制,使用非对称密钥加密用于传输对称密钥来保证传输过程的安全性,之后使用对称密钥加密进行通信来保证通信过程的效率。
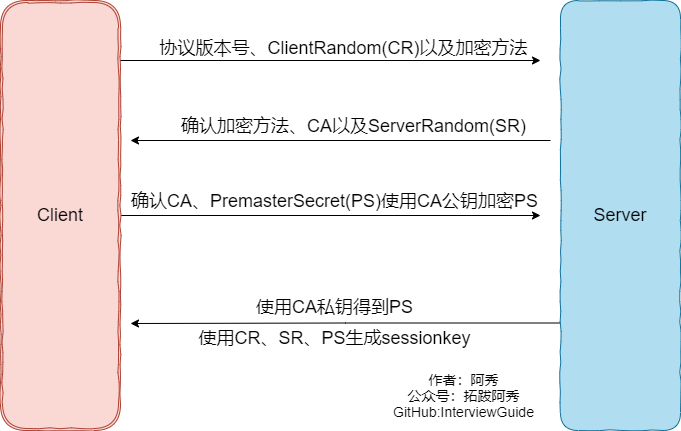
确保传输安全过程(其实就是rsa原理):
- Client给出协议版本号、一个客户端生成的随机数(Client random),以及客户端支持的加密方法。
- Server确认双方使用的加密方法,并给出数字证书、以及一个服务器生成的随机数(Server random)。
- Client确认数字证书有效,然后生成呀一个新的随机数(Premaster secret),并使用数字证书中的公钥,加密这个随机数,发给Server。
- Server使用自己的私钥,获取Client发来的随机数(Premaster secret)。
- Client和Server根据约定的加密方法,使用前面的三个随机数,生成”对话密钥”(session key),用来加密接下来的整个对话过程。
四大算法
拥塞控制主要是四个算法:1)慢启动,2)拥塞避免,3)拥塞发生,4)快速恢复。这四个算法不是一天都搞出来的,这个四算法的发展经历了很多时间,到今天都还在优化中。

所谓慢启动,也就是TCP连接刚建立,一点一点地提速,试探一下网络的承受能力,以免直接扰乱了网络通道的秩序。 慢启动算法
- 连接建好的开始先初始化拥塞窗口cwnd大小为1,表明可以传一个MSS大小的数据。
- 每当收到一个ACK,cwnd大小加一,呈线性上升。
- 每当过了一个往返延迟时间RTT(Round-Trip Time),cwnd大小直接翻倍,乘以2,呈指数让升。
- 还有一个ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”(后面会说这个算法)
如同前边说的,当拥塞窗口大小cwnd大于等于慢启动阈值ssthresh后,就进入拥塞避免算法。算法如下:
- 收到一个ACK,则cwnd = cwnd + 1 / cwnd
- 每当过了一个往返延迟时间RTT,cwnd大小加一。 过了慢启动阈值后,拥塞避免算法可以避免窗口增长过快导致窗口拥塞,而是缓慢的增加调整到网络的最佳值。
一般来说,TCP拥塞控制默认认为网络丢包是由于网络拥塞导致的,所以一般的TCP拥塞控制算法以丢包为网络进入拥塞状态的信号。对于丢包有两种判定方式,一种是超时重传RTO[Retransmission Timeout]超时,另一个是收到三个重复确认ACK。
超时重传是TCP协议保证数据可靠性的一个重要机制,其原理是在发送一个数据以后就开启一个计时器,在一定时间内如果没有得到发送数据报的ACK报文,那么就重新发送数据,直到发送成功为止。
但是如果发送端接收到3个以上的重复ACK,TCP就意识到数据发生丢失,需要重传。这个机制不需要等到重传定时器超时,所以叫 做快速重传,而快速重传后没有使用慢启动算法,而是拥塞避免算法,所以这又叫做快速恢复算法。
超时重传RTO[Retransmission Timeout]超时,TCP会重传数据包。TCP认为这种情况比较糟糕,反应也比较强烈:
- 由于发生丢包,将慢启动阈值ssthresh设置为当前cwnd的一半,即ssthresh = cwnd / 2.
- cwnd重置为1
- 进入慢启动过程
最为早期的TCP Tahoe算法就只使用上述处理办法,但是由于一丢包就一切重来,导致cwnd又重置为1,十分不利于网络数据的稳定传递。
所以,TCP Reno算法进行了优化。当收到三个重复确认ACK时,TCP开启快速重传Fast Retransmit算法,而不用等到RTO超时再进行重传:
- cwnd大小缩小为当前的一半
- ssthresh设置为缩小后的cwnd大小
- 然后进入快速恢复算法Fast Recovery。
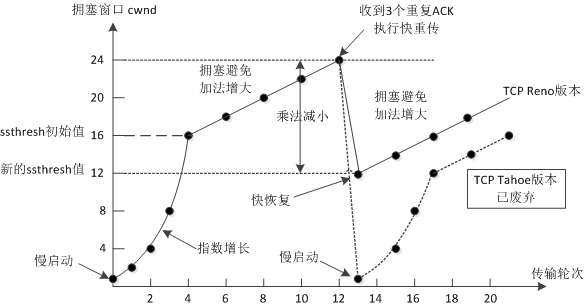
TCP Tahoe是早期的算法,所以没有快速恢复算法,而Reno算法有。在进入快速恢复之前,cwnd和ssthresh已经被更改为原有cwnd的一半。快速恢复算法的逻辑如下:
- cwnd = cwnd + 3 MSS,加3 MSS的原因是因为收到3个重复的ACK。
- 重传DACKs指定的数据包。
- 如果再收到DACKs,那么cwnd大小增加一。
- 如果收到新的ACK,表明重传的包成功了,那么退出快速恢复算法。将cwnd设置为ssthresh,然后进入拥塞避免算法。
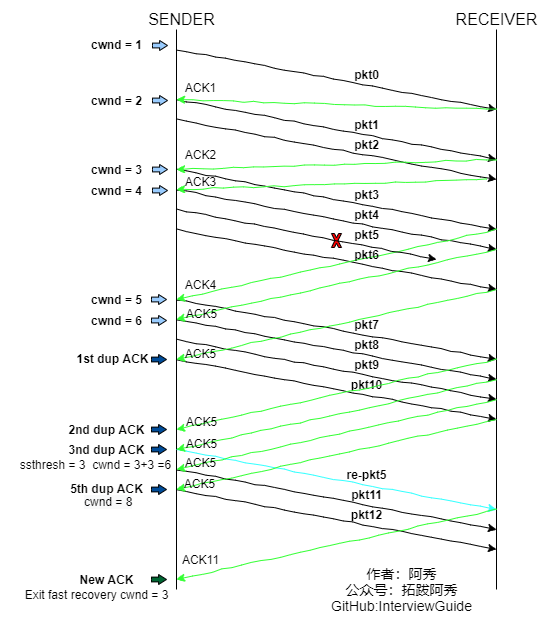
如图所示,第五个包发生了丢失,所以导致接收方接收到三次重复ACK,也就是ACK5。所以将ssthresh设置当当时cwnd的一半,也就是6/2 = 3,cwnd设置为3 + 3 = 6。然后重传第五个包。当收到新的ACK时,也就是ACK11,则退出快速恢复阶段,将cwnd重新设置为当前的ssthresh,也就是3,然后进入拥塞避免算法阶段。
- 目的是接收方通过TCP头窗口字段告知发送方本方可接收的最大数据量,用以解决发送速率过快导致接收方不能接收的问题。所以流量控制是点对点控制。
- TCP是双工协议,双方可以同时通信,所以发送方接收方各自维护一个发送窗和接收窗。
- 发送窗:用来限制发送方可以发送的数据大小,其中发送窗口的大小由接收端返回的TCP报文段中窗口字段来控制,接收方通过此字段告知发送方自己的缓冲(受系统、硬件等限制)大小。
- 接收窗:用来标记可以接收的数据大小。
- TCP是流数据,发送出去的数据流可以被分为以下四部分:已发送且被确认部分 | 已发送未被确认部分 | 未发送但可发送部分 | 不可发送部分,其中发送窗 = 已发送未确认部分 + 未发但可发送部分。接收到的数据流可分为:已接收 | 未接收但准备接收 | 未接收不准备接收。接收窗 = 未接收但准备接收部分。
- 发送窗内数据只有当接收到接收端某段发送数据的ACK响应时才移动发送窗,左边缘紧贴刚被确认的数据。接收窗也只有接收到数据且最左侧连续时才移动接收窗口。
- 确认和重传:接收方收到报文就会确认,发送方发送一段时间后没有收到确认就会重传。
- 数据校验:TCP报文头有校验和,用于校验报文是否损坏。
- 数据合理分片和排序:tcp会按最大传输单元(MTU)合理分片,接收方会缓存未按序到达的数据,重新排序后交给应用层。而UDP:IP数据报大于1500字节,大于MTU。这个时候发送方的IP层就需要分片,把数据报分成若干片,是的每一片都小于MTU。而接收方IP层则需要进行数据报的重组。由于UDP的特性,某一片数据丢失时,接收方便无法重组数据报,导致丢弃整个UDP数据报。
- 流量控制:当接收方来不及处理发送方的数据,能通过滑动窗口,提示发送方降低发送的速率,防止包丢失。
- 拥塞控制:当网络拥塞时,通过拥塞窗口,减少数据的发送,防止包丢失。
| 状态码 | 类别 | 含义 |
|---|---|---|
| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出 |
100 Continue :表明到目前为止都很正常,客户端可以继续发送请求或者忽略这个响应。
- 200 OK
- 204 No Content :请求已经成功处理,但是返回的响应报文不包含实体的主体部分。一般在只需要从客户端往服务器发送信息,而不需要返回数据时使用。
- 206 Partial Content :表示客户端进行了范围请求,响应报文包含由 Content-Range 指定范围的实体内容。
- 301 Moved Permanently :永久性重定向
- 302 Found :临时性重定向
- 303 See Other :和 302 有着相同的功能,但是 303 明确要求客户端应该采用 GET 方法获取资源。
- 304 Not Modified :如果请求报文首部包含一些条件,例如:If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since,如果不满足条件,则服务器会返回 304 状态码。
- 307 Temporary Redirect :临时重定向,与 302 的含义类似,但是 307 要求浏览器不会把重定向请求的 POST 方法改成 GET 方法。
- 400 Bad Request :请求报文中存在语法错误。
- 401 Unauthorized :该状态码表示发送的请求需要有认证信息(BASIC 认证、DIGEST 认证)。如果之前已进行过一次请求,则表示用户认证失败。
- 403 Forbidden :请求被拒绝。
- 404 Not Found
- 500 Internal Server Error :服务器正在执行请求时发生错误。
- 503 Service Unavailable :服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。