 gyzboy的十万个为什么
gyzboy的十万个为什么
集合
-
不会,经过trimToSize的话,会申请2的n次幂大小空间,乘以0.75系数后也足够10000条数据使用
-
java8中的扰动函数:(h = key.hashCode()) ^ (h »> 16),作用是为了增加hash的随机性
-
会找最近的2的幂次方,17的话,最初大小为2的5次方=32
-
数组+链表+红黑树,当链表长度大于等于 8 并且数组长度大于 64,就会转为红黑树
-
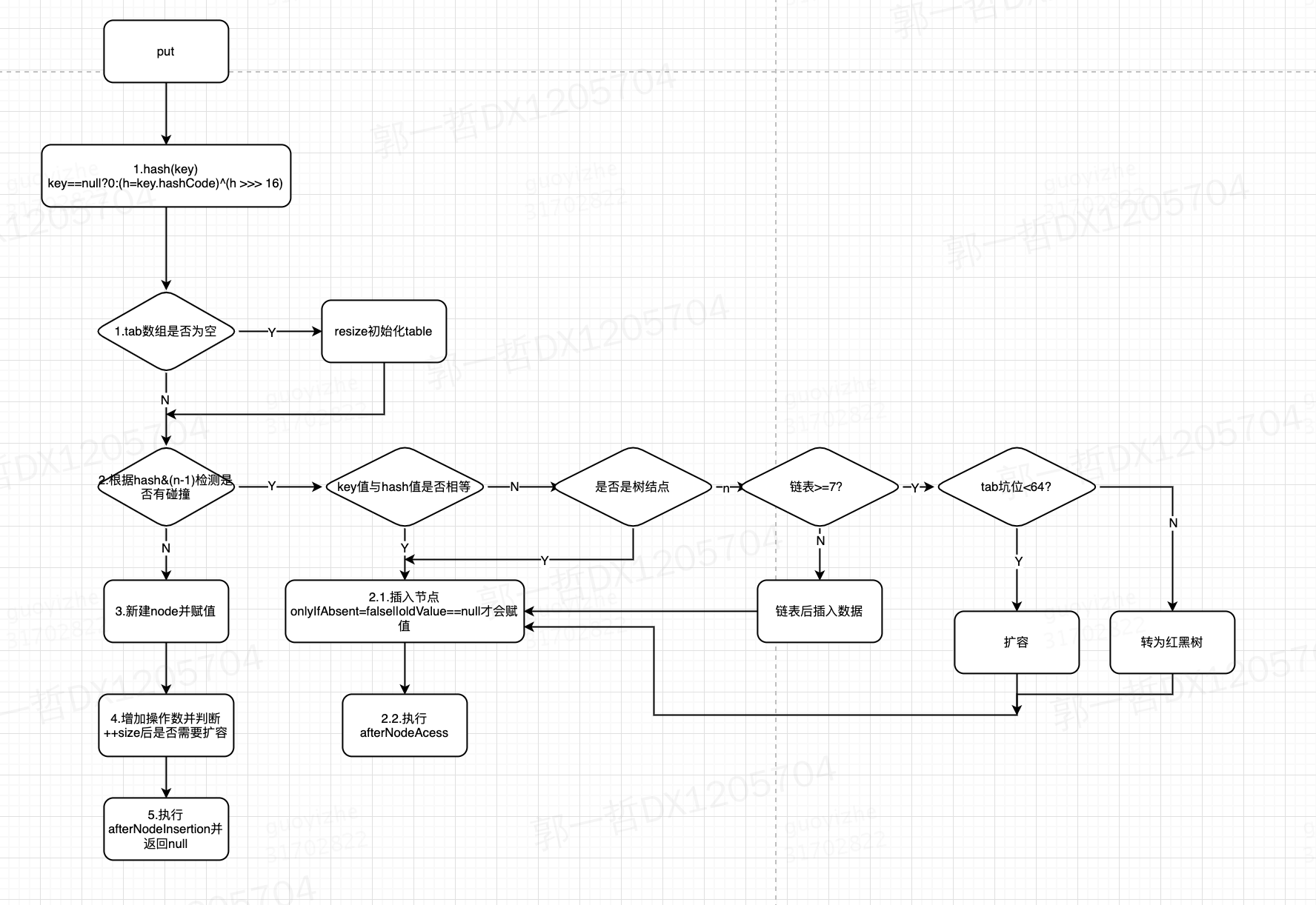
- 1、根据 key 通过该公式 (h = key.hashCode()) ^ (h »> 16) 计算 hash 值
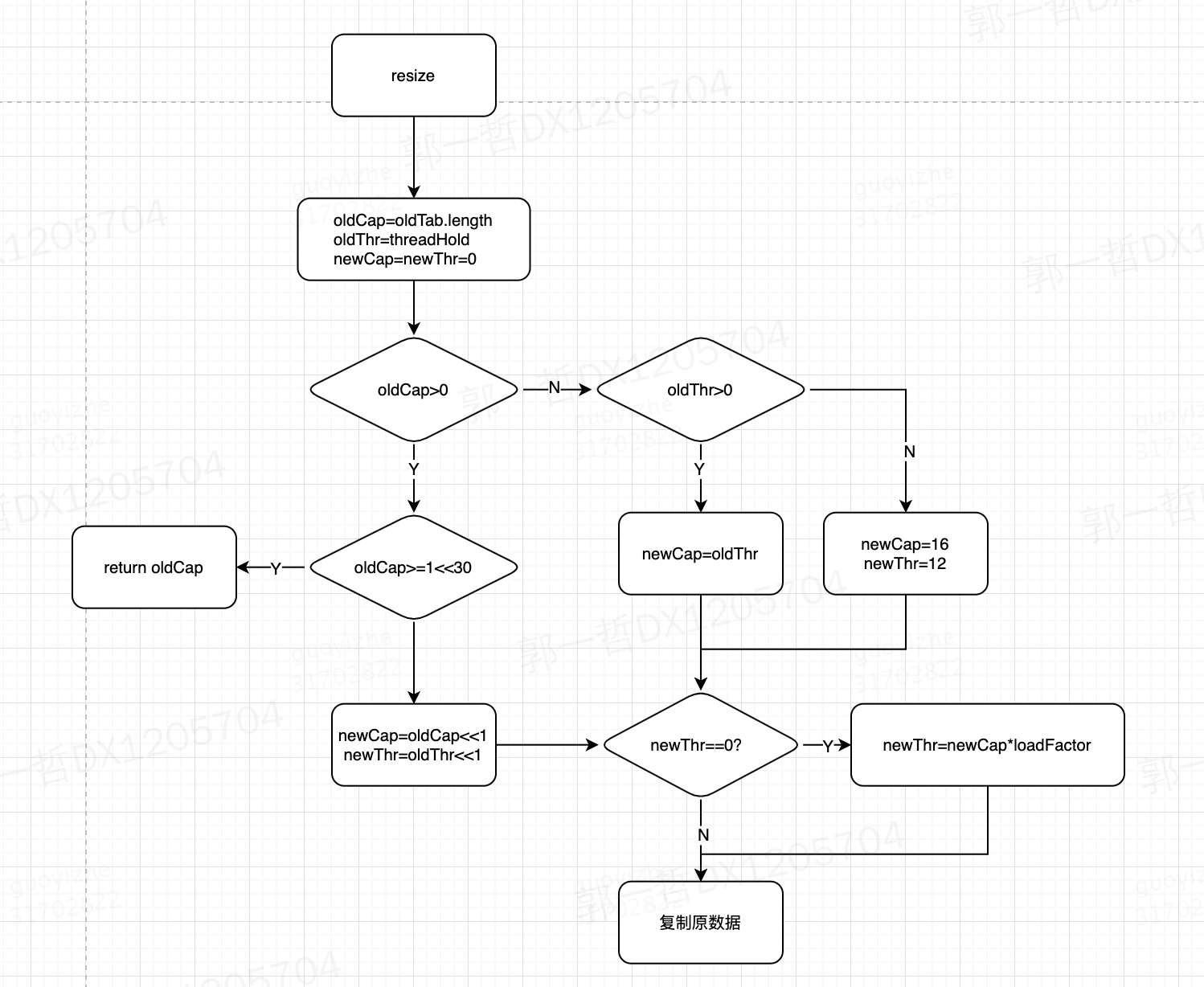
- 2、判断 HashMap table 数组是否已经初始化,如果没有初始化,那么就按照默认 16 的大小进行初始化,扩容阀值也将按照 size * 0.75 来定义
- 3、通过该公式 (n - 1) & hash 拿到存入 table 的 index 索引,判断当前索引下是否有值,如果没有值就进行直接赋值 tab[index] , 如果有值,那么就会发生 hash 碰撞 💥 ,也就是俗称 hash冲突 , 在 JDK中的解决是的办法有 2 个,其一是链表,其二是 红黑树。
- 4、当发送 hash 冲突 首先判断数组中已存入的 key 是否与当前存入的 key 相同,并且内存地址也一样,那么就直接默认直接覆盖 values
- 5、如果 key 不相等,那么先拿到 tab[index] 中的 Node是否是红黑树,如果是红黑树,那么就加入红黑树的节点;如果 Node 节点不是红黑树,那么就直接放入 node 的 next 下,形成单链表结构。
- 6、如果链表结构的长度 >= 8 就转为红黑树的结构。
- 7、最后检查扩容机制
-
- 1、首先判断新增的节点在红黑树上是不是已经存在,判断手段有如下两种
- 1.1、如果节点没有实现 Comparable 接口,使用 equals 进行判断;
- 1.2、如果节点自己实现了 Comparable 接口,使用 compareTo 进行判断。
- 2、新增的节点如果已经在红黑树上,直接返回;不在的话,判断新增节点是在当前节点的左边还是右边,左边值小,右边值大;
- 3、自旋递归 1 和 2 步,直到当前节点的左边或者右边的节点为空时,停止自旋,当前节点即为我们新增节点的父节点;
- 4、把新增节点放到当前节点的左边或右边为空的地方,并于当前节点建立父子节点关系;
- 5、进行着色和旋转,结束。
-
链表查询的时间复杂度是 O (n),红黑树的查询复杂度是 O (log (n))。在链表数据不多的时候,使用链表进行遍历也比较快,只有当链表数据比较多的时候,才会转化成红黑树,但红黑树需要的占用空间是链表的 2 倍,考虑到转化时间和空间损耗,所以我们需要定义出转化的边界值
-
- 来是比取余操作更加有效率
- 只有当数组长度为2的幂次方时,h&(length-1)才等价于h%length
- 解决了“哈希值与数组大小范围不匹配”的问题
-
hashCode()方法返回的是int整数类型,其范围为-(2^31)~(2^31-1),约有40亿个映射空间,而HashMap的容量范围是在16(初始化默认值)~2 ^ 30,HashMap通常情况下是取不到最大值的,并且设备上也难以提供这么多的存储空间,从而导致通过hashCode()计算出的哈希值可能不在数组大小范围内,进而无法匹配存储位置
-
public ArrayList(int initialCapacity) { if (initialCapacity > 0) { this.elementData = new Object[initialCapacity];//transient } else if (initialCapacity == 0) { this.elementData = EMPTY_ELEMENTDATA; } else { throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity); } } public void add(int index, E element) { if (index > size || index < 0) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); ensureCapacityInternal(size + 1); // Increments modCount!!,执行扩容操作 System.arraycopy(elementData, index, elementData, index + 1, size - index); elementData[index] = element; size++; } private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1);//扩容为原来的1.5倍 if (newCapacity - minCapacity < 0)//minCapacity = currSize+1 newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0)//MAX_ARRAY_SIZE=Integer.MAX_VALUE - 8 newCapacity = hugeCapacity(minCapacity);//minCapacity<0 抛出oom // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); } public E remove(int index) { if (index >= size) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); modCount++; E oldValue = (E) elementData[index]; int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // clear to let GC do its work return oldValue; } public boolean remove(Object o) { if (o == null) { for (int index = 0; index < size; index++) if (elementData[index] == null) { fastRemove(index); return true; } } else { for (int index = 0; index < size; index++) if (o.equals(elementData[index])) { fastRemove(index); return true; } } return false; } // 1.ArrayList 底层实现是基于数组的,因此对指定下标的查找和修改比较快,但是删除和插入操作比较慢。 // 2.构造 ArrayList 时尽量指定容量,减少扩容时带来的数组复制操作,如果不知道大小可以赋值为默认容量 10。 // 3.每次添加元素之前会检查是否需要扩容,每次扩容都是增加原有容量的一半。 // 4.每次对下标的操作都会进行安全性检查,如果出现数组越界就立即抛出异常。 // 5.ArrayList 的所有方法都没有进行同步,因此它不是线程安全的。 // 6.扩容机制,扩容到1.5->扩容到指定大小->扩容到最大Int // 7.删除就是找到元素变更的索引,然后通过System.arraycopy进行数组移动
-
- 线程安全的,多线程环境下可以直接使用,无需加锁;
- 通过锁 + 数组拷贝 + volatile 关键字保证了线程安全;
- 每次数组操作,都会把数组拷贝一份出来,在新数组上进行操作,操作成功之后再赋值回去
public boolean add(E e) { final ReentrantLock lock = this.lock; //加锁 lock.lock(); try { // 得到所有的原数组 Object[] elements = getArray(); int len = elements.length; //拷贝到新数组里面,新数组的长度是 + 1 的 Object[] newElements = Arrays.copyOf(elements, len + 1); //在新数组中进行赋值,新元素直接放在数组的尾部 newElements[len] = e; //替换原来的数组 setArray(newElements); return true; } finally { lock.unlock(); } } // 1、通过可重入互斥锁 ReentrantLock对 add(E) 加锁 // 2、通过 getArray() 方法得到已经存在的数组 // 3、实例化一个长度为当前 size + 1 的数组,然后将 getArray 的数组放入新数组中 // 4、最后将添加的数据存入新数组的最后索引中 // 5、基于当前类中的 setArray(newElements); 来替换缓存中的数组数据,因为它在类中中被 volatile 修饰了,所以只要内存地址一变,那么就会立马通知,其它 CPU 的缓存让它得到更新。 // 6、释放可重入互斥锁 -
是为了触发地址改变,是voliate关键字起效,将改变通知到其他线程
-
- put操作:
- 数组初始化时通过自旋 + CAS + 双重 check 等手段保证了数组初始化时的线程安全
- 新增槽点时的线程安全
- 通过自旋死循环保证一定可以新增成功。
- 当前槽点为空时,通过 CAS 新增。
- 当前槽点有值,通过sychronized锁住当前槽点。
- 红黑树旋转时,通过CAS锁住红黑树的根节点
- 扩容时的线程安全
- 拷贝槽点时,会把原数组的槽点锁住
- 拷贝成功之后,会把原数组的槽点设置成转移节点,这样如果有数据需要 put 到该节点时,发现该槽点是转移节点,会一直等待,直到扩容成功之后,才能继续 put
- 从尾到头进行拷贝,拷贝成功就把原数组的槽点设置成转移节点
-
LinkedHashMap是一个单向的链表结构
- put操作 默认会按照插入顺序,插入到队尾,会通过afterNodeInsertion删除头部元素
- get操作 会将最后访问的元素移动到队尾
-
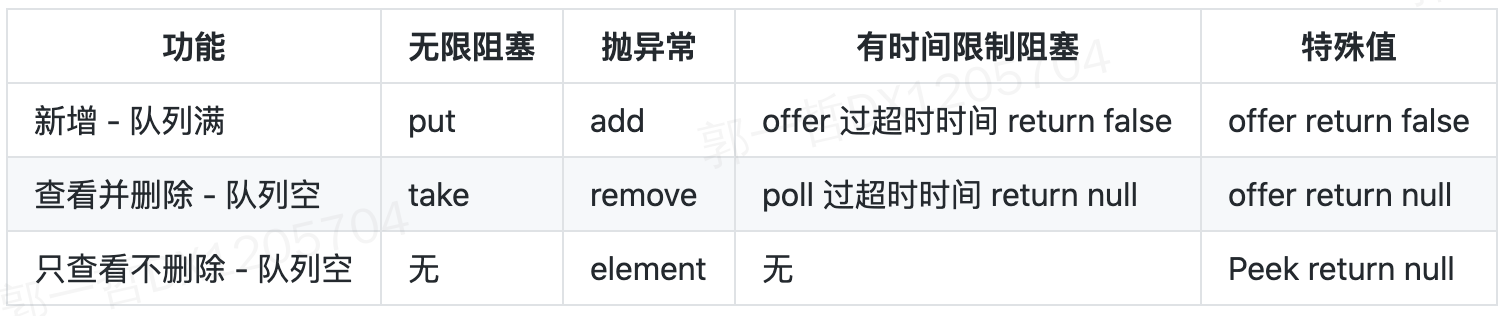
- 遇到队列满或空的时候,抛异常,如 add、remove、element;
- 遇到队列满或空的时候,返回特殊值,如 offer、poll、peek。
-
- 有界的阻塞数组,容量一旦创建,后续大小无法修改;
- 元素是有顺序的,按照先入先出进行排序,从队尾插入数据数据,从队头拿数据;
- 队列满时,往队列中 put 数据会被阻塞,队列空时,往队列中拿数据也会被阻塞。
-
- LinkedBlockingQueue 链表阻塞队列和 ArrayBlockingQueue 数组阻塞队列是一类,前者容量是 Integer 的最大值,后者数组大小固定,两个阻塞队列都可以指定容量大小,当队列满时,如果有线程 put 数据,线程会阻塞住,直到有其他线程进行消费数据后,才会唤醒阻塞线程继续 put,当队列空时,如果有线程 take 数据,线程会阻塞到队列不空时,继续 take。
- SynchronousQueue 同步队列,当线程 put 时,必须有对应线程把数据消费掉,put 线程才能返回,当线程 take 时,需要有对应线程进行 put 数据时,take 才能返回,反之则阻塞,举个例子,线程 A put 数据 A1 到队列中了,此时并没有任何的消费者,线程 A 就无法返回,会阻塞住,直到有线程消费掉数据 A1 时,线程 A 才能返回。
-
Q:假设 SynchronousQueue 底层使用的是堆栈,线程 1 执行 take 操作阻塞住了,然后有线程 2 执行 put 操作,问此时线程 2 是如何把 put 的数据传递给 take 的?
首先线程 1 被阻塞住,此时堆栈头就是线程 1 了,此时线程 2 执行 put 操作,会把 put 的数据赋值给堆栈头的 match 属性,并唤醒线程 1,线程 1 被唤醒后,拿到堆栈头中的 match 属性,就能够拿到 put 的数据了。
严格上说并不是 put 操作直接把数据传递给了 take,而是 put 操作改变了堆栈头的数据,从而 take 可以从堆栈头上直接拿到数据,堆栈头是 take 和 put 操作之间的沟通媒介
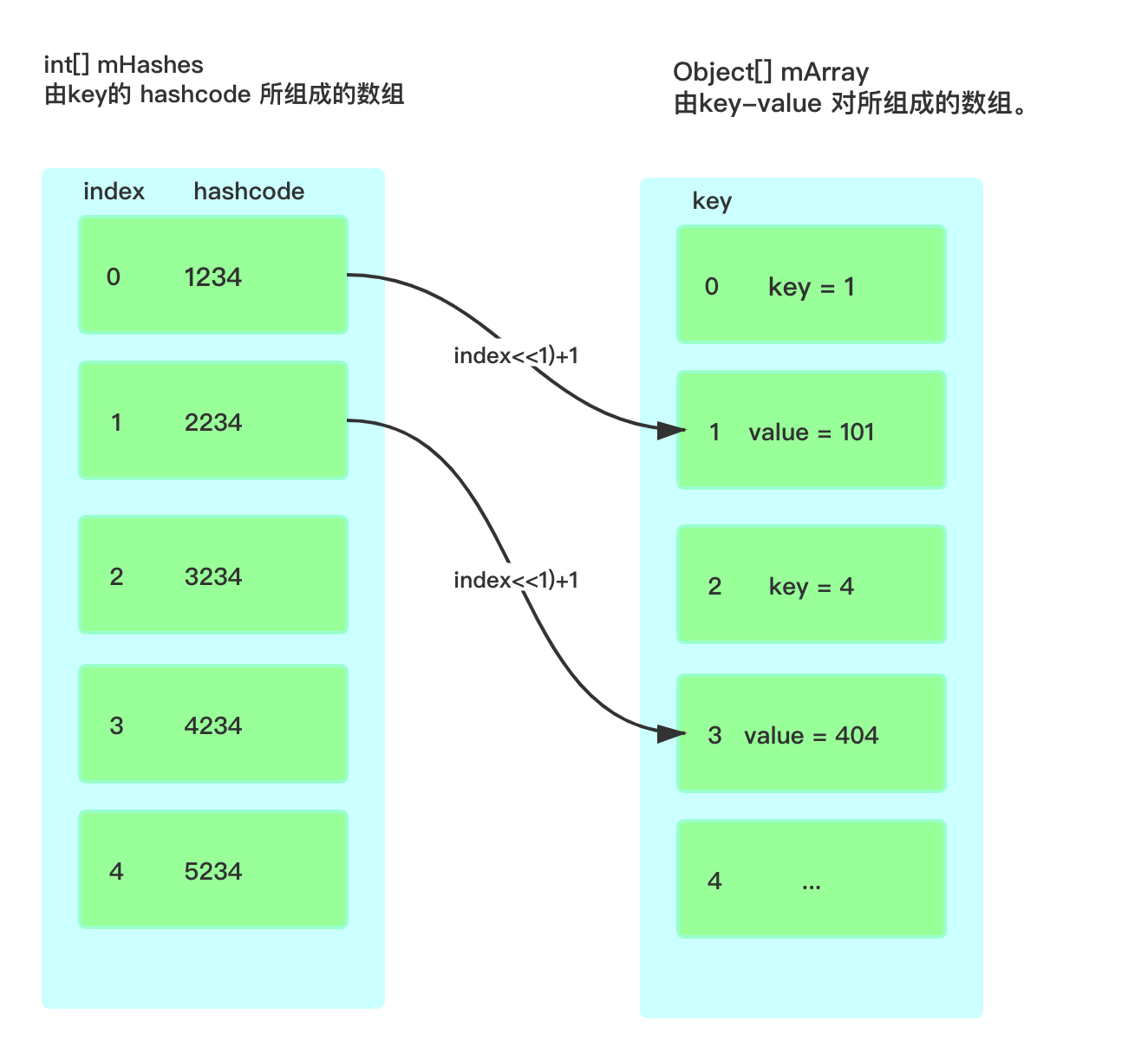 ArrayMap 底层通过两个数组来建立映射关系,其中 int[] mHashes 按大小顺序保存 Key 对象 hashCode 值,Object[] mArray 按 mHashes 的顺序用相邻位置保存 Key 对象和 Value 对象。mArray 长度 是 mHashes 长度的 2 倍
ArrayMap 底层通过两个数组来建立映射关系,其中 int[] mHashes 按大小顺序保存 Key 对象 hashCode 值,Object[] mArray 按 mHashes 的顺序用相邻位置保存 Key 对象和 Value 对象。mArray 长度 是 mHashes 长度的 2 倍
它的底层还是红黑树结构,跟 HashMap 的红黑树是一样的。然后 TreeMap 是利用了红黑树左大右小的性质,根据 key 来进行排序的
- 判断红黑树的节点是否为空,为空的话,新增的节点直接作为根节点
- 根据红黑树左小右大的特性,进行判断,找到应该新增节点的父节点
- 在父节点的左边或右边插入新增节点
- 着色旋转,达到平衡,结束。
//HashMap.HashMapEntry
final K key;
V value;
HashMapEntry<K,V> next;
int hash;
//ConcurrentHashMap.Node
final K key;
volatile V val;
volatile Node<K,V> next;
final int hash;
当每次进行类似add、remove操作时,都会对操作数modCount执行+1操作,在使用迭代器等进行迭代操作时,会判断modCount与期望modCount的值,如果不相等就抛出ConcurrentModificationException
Collection.sort():排序算法,Comparator Collection.binarySearch():二分查找 Collections.shuffle():洗牌算法,随机数 Collections.rotate():旋转算法,将list中的元素形成一个环,顺时针旋转n位